Digital Marketing
The managment of digital advertising campaigns is a complex and dynamic process, and still requires often human work to optimize the delivery of ads to maximize the desired outcome, such as smooth and evenly distributed impression delivery over time. By leveraging Reinforcement Learning (RL), we can optimize the delivery of ads to support or automate human campaign managment. This notebook demonstrates the use of pi_optimal to train an RL agent for ad delivery optimization, utilizing a dataset of historical ad data, about the campiagns delevery as well as the campaign manager's actions.
Problem Statement
We aim to automate and optimize campaign management for a marketing agency specializing in regional online advertising. Due to the limited geographical scope, achieving smooth and consistent ad delivery over time presents a significant challenge. The agency has provided a dataset of historical ad delivery data. Leveraging pi_optimal, our goal is to train a RL agent capable of:
- Delivering ads in a smooth, linear, and efficient manner throughout the entire campaign duration.
This approach seeks to enhance campaign performance, ensure better resource utilization, and improve audience targeting within regional constraints.
Dataset
The dataset contains 57 adsets which data was collected between the 15th of July 2024 and 13th of November 2024. Every hour a snapshot of the adset state was taken, including the number of impressions delivered by the adset. The dataset also includes the actions taken by the campaign manager to adjust the adset delivery.
The dataset contains the following columns:
Dataset Features
-
AdSet General Information:
created_at: The date and time where the state and actions of the adset was recorded.unit_index: The unique identifier of the adset.hour_of_day: The hour of the day when the adset datapoint was recorded.day_of_week: The day of the week when the adset datapoint was recorded.adset_name: The name of the adset.
-
AdSet Delivery Information:
adset_impressions_diff: The number of impressions delivered in this hour.adset_settings_total_budget: The total budget of the adset.adset_settings_daily_budget: The daily budget of the adset.adset_settings_maximum_daily_impressions: The maximum number of impressions the adset can deliver in a day.adset_settings_maximum_lifetime_impressions: The maximum number of impressions the adset can deliver in its lifetime.adset_settings_runtime_in_hours: The total number of hours the adset is going to run.adset_settings_remaining_hours: The remaining number of hours the adset will run.adset_settings_running_hours: The number of hours the adset has been running.
-
Campaign Manager Actions:
adset_settings_maximum_cpm: The maximum CPM set for a specific hour by the campaign manager.adset_targetings_frequency_capping_requests: The frequency capping requests used by the campaign manager. Frequency capping is a feature that limits the number of times an ad is shown to the same user.adset_settings_bidding_strategy: The bidding strategy method.adset_settings_pacing_type: The pacing type of the campaign. Pacing is the rate at which the adset spends its budget.
-
AdSet Delivery Metrics:
total_missing_impressions: The total number of missing impressions of the total number of impression.expected_impression_next_hour: The expected number of impressions the adset will deliver in the next hour.hourly_missing_impressions: The number of missing impressions in this hour.
import pandas as pd
df_historical_adset_control = pd.read_csv('data/historical_adset_control.csv', parse_dates=['created_at'])
df_historical_adset_control.head()
Speeding up Training and Inference
In case you have an Intel CPU and have installed the sklearnex package, you can speed up the training and inference of the RL agent by uncommenting the following lines:
# Uncomment the following lines for faster training and inference if you have sklearnex installed and are using an Intel CPU
#import numpy as np
#from sklearnex import patch_sklearn
#patch_sklearn()
Defining the Reward Function
The reward function is quite simple and just wants to minimize the hourly missing impressions. The reward function is defined as follows:
where the penalty is defined as:
The expected impressions for the next hour are calculated as:
and the total missing impressions are given by:
Implementation
# Function to calculate reward
def calculate_reward(row, epsilon=1e-8):
# Calculate the total missing impressions
total_missing_impressions = row.adset_settings_maximum_lifetime_impressions - row.adset_impressions
# Calculate the expected impressions in the next hour (epsilon is added to avoid division by zero)
expected_impression_next_hour = (total_missing_impressions / (row.adset_settings_remaining_hours + epsilon))
expected_impression_next_hour = max(0, expected_impression_next_hour)
# Calculate the hourly missing impressions which prepresents the performance of the current control settings
# when a lot of impressions are missing, the control settings were not optimal
hourly_missing_impressions = ((expected_impression_next_hour - row.adset_impressions_diff) ** 2) ** 0.5
# Total penalty
total_penalty = hourly_missing_impressions
# Reward is the negative of the total penalty
reward = -total_penalty
return reward
Apply the reward function to the dataset
# Apply the reward calculation
df_historical_adset_control['reward'] = df_historical_adset_control.apply(calculate_reward, axis=1)
df_historical_adset_control.head()
Dataset Preparation
To train a pi_optimal RL agent, we must first load and preprocess the ad dataset. The pi_optimal package provides a custom dataset class that streamlines the preprocessing pipeline. Below are the key parameters that need to be defined during this process:
-
Unit Index:
This parameter,unit_index, identifies distinct units in the dataset. In our case, each unit corresponds to unique adset (unit_indexcolumn). -
Time Column:
The time column (timestep_column) establishes the temporal sequence of data points, enabling the model to learn from historical trends. For instance, the RL agent can consider the previous 24 hours of data (set by thelookback_timestepsparameter) to make informed decisions. In our case we would use the datetime columncreated_at. -
Reward Column:
Thereward_columnspecifies the target that the agent seeks to optimize. Here, we previously calculated and added therewardcolumn to the dataset, which reflects just the distance between the current total impressions and the expected current impression given the progression of the campaign. -
State Columns:
The state columns capture the system's current status, it includes all variables that influence campaigns delivery performance. Relevant examples include:adset_targetings_total_populationadset_settings_total_budgetday_of_week- ...
These features help the agent assess the current environment and predict outcomes effectively.
-
Action Columns:
The action columns represent controllable variables, such as the CPM set or the frequency capping settingy. As you can see there are multiple action which we try to optimize at the same time.
By carefully defining these parameters, we ensure that the RL agent can interpret the dataset's structure, learn from past patterns, and make optimized decisions to optimize adset delivery.
Dataset Preparation
state_cols = [
'hour_of_day',
'day_of_week',
'adset_name',
'adset_impressions_diff',
'adset_settings_total_budget',
'adset_settings_daily_budget',
'adset_settings_maximum_daily_impressions',
'adset_settings_maximum_lifetime_impressions',
'adset_settings_runtime_in_hours',
'adset_settings_remaining_hours',
'adset_settings_running_hours',
'adset_targetings_total_population',
]
action_cols = [
'adset_settings_maximum_cpm',
'adset_targetings_frequency_capping_requests',
'adset_settings_bidding_strategy',
'adset_settings_pacing_type',
]
reward_col = 'reward'
timestamp_col = 'created_at'
unit_col = 'unit_index'
Configuration
Beides the columns mentioned above, we could also adjust the number of lookback timesteps for predicting hwo the campaign will evolve in the future. In our case we consider the last 12 hours of data to make a decision.
import pi_optimal as po
LOOKBACK_TIMESTEPS = 8
historical_dataset = po.datasets.timeseries_dataset.TimeseriesDataset(df=df_historical_adset_control,
state_columns=state_cols,
action_columns=action_cols,
reward_column=reward_col,
timestep_column=timestamp_col,
unit_index=unit_col,
lookback_timesteps=LOOKBACK_TIMESTEPS)
Agent Initialization and Training
With the dataset prepared, the next crucial step is to initialize and train the RL agent. This agent will learn to model the dynamics of the regional online advertising market, enabling it to make informed decisions based on the environment's behavior.
from pi_optimal.agents.agent import Agent
agent = Agent()
agent.train(dataset=historical_dataset)
Evaluation and Action Prediction
After training the RL agent, the next step is to evaluate its performance on new, unseen data. This involves loading data of a running campaign, preparing it using the same preprocessing pipeline as the historical dataset, and then using the trained agent to predict the optimal actions (i.e., adjustments to maxCPM, frequency capping, or bidding strategy) to optmize the delivery objective.
Load Current Data
# Load the current adset control data
df_current_adset_control = pd.read_csv('data/current_adset_control.csv', parse_dates=['created_at'])
# Apply the reward calculation
df_current_adset_control["reward"] = df_current_adset_control.apply(calculate_reward, axis=1)
Create Current Dataset
current_dataset = po.datasets.timeseries_dataset.TimeseriesDataset(df=df_current_adset_control,
dataset_config=historical_dataset.dataset_config,
train_processors=False,
is_inference=True)
Predict Optimal Actions
best_actions = agent.predict(current_dataset, inverse_transform=True, n_iter=15)
Interpreting the Results
The agent provides a sequence of optimal actions for the time horizon. Here we print them:
for i in range(len(best_actions)):
print(f"Timestep {i}:")
print("Maximum CPM:", best_actions[i][0])
print("Frequency Capping:", best_actions[i][1])
print("Bidding Strategy:", best_actions[i][2])
print("Pacing Type:", best_actions[i][3])
print()
print("--------------------")
print()
Multi-Step Planning
The agent optimizes actions by considering future outcomes over a multi-step horizon. This allows for efficient and forward-thinking decision-making.
Decision-Making Options
-
Full Application of Recommended Actions: We could choose to apply all recommended actions immediately, for example adjusting maximum cpm, frequency capping, bidding strategy or pacing according to the agent's suggestions for the entire time horizon (e.g., the next 4 hours). Therefore the campaign will be controled based on the agent’s full plan.
-
Incremental Application: Alternatively, we might apply only the first action in the sequence for the next hour and then the next hour re-run the agent to generate updated recommendations. This method provides flexibility by allowing adjustments based on real-time conditions, while still leveraging the agent’s ability to look multiple steps ahead.
Visualization
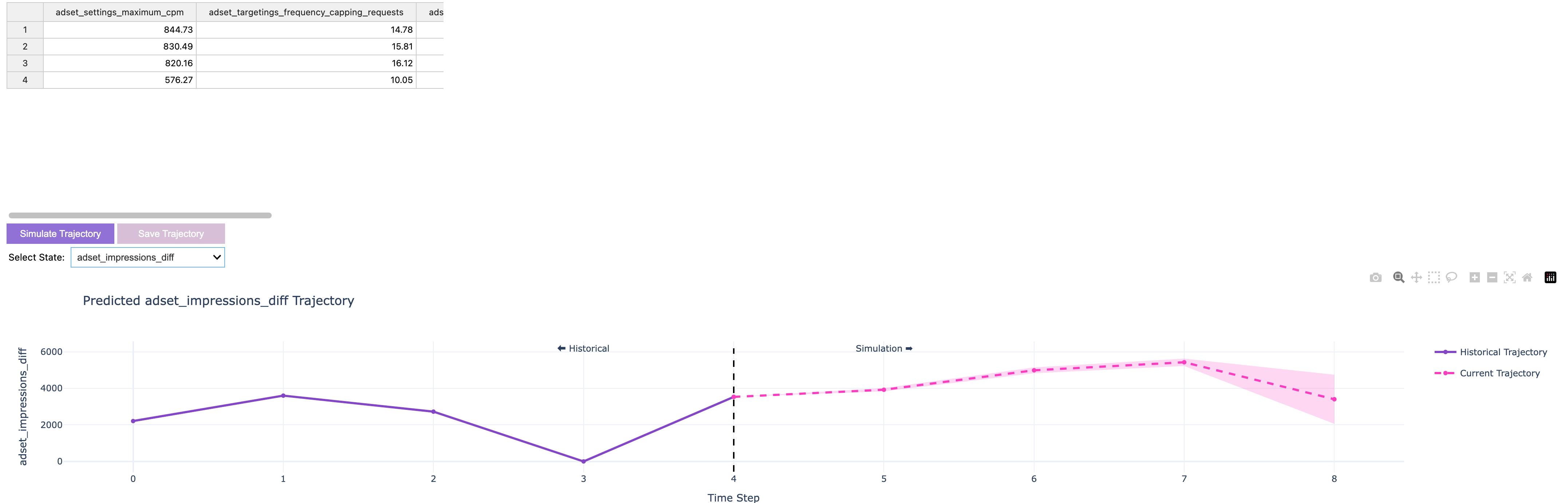
pi_optimal includes a trajectory visualizer for the simulated optimal trajectory. This tool allows you to explore the agent's recommendations and analyze their effects on energy consumption and indoor temperature over time. It provides valuable insights into the agent's behavior and helps evaluate its performance across various scenarios.
from pi_optimal.utils.trajectory_visualizer import TrajectoryVisualizer
trajectory_visualizer = TrajectoryVisualizer(agent, current_dataset, best_actions=best_actions)
trajectory_visualizer.display()
Conclusion
This notebook demonstrates how pi_optimal could be used to optimize ad delivery for regional online advertising campaigns. By training a RL agent on historical ad data, we can automate and optimize ad campaigns, ensuring smooth and efficient ad delivery over time. The agent learns to make informed decisions based on the environment's behavior, enabling it to maximize the desired outcome and improve resource utilization.
Key Highlights
- Dataset Preparation: We loaded and preprocessed the ad dataset, defining key parameters such as unit index, time column, reward column, state columns, and action columns.
- Data Type Agnostic Actions:
pi_optimalsupports a wide range of actions, including continuous, discrete, and multi-dimensional actions. This flexibility allows you to model complex systems and optimize a variety of objectives. Especially in the context of ad tech, where multiple actions can be taken to optimize delivery.
Next Steps
-
Fine-Tuning the Reward Function: Experiment with different reward functions to further optimize ad delivery performance. For example, you could consider additional factors such as budget utilization, audience targeting, or campaign reach.
-
Hyperparameter Tuning: Optimize the agent's hyperparameters to enhance its performance and generalization capabilities. You could explore different neural network architectures, learning rates, or optimization algorithms to improve the agent's learning efficiency.
-
Real-Time Decision-Making: Extend the agent's capabilities to support real-time decision-making. By integrating the agent with live data streams, you can optimize ad delivery in dynamic and rapidly changing environments.
References
pi_optimalDocumentation: GitHub