Temperature Optimization
Efficient energy management in buildings is crucial for reducing operational costs and minimizing environmental impact. Leveraging advanced machine learning techniques, particularly Reinforcement Learning (RL), can significantly enhance decision-making processes related to energy usage. This notebook demonstrates how to utilize a dataset of building energy consumption to train and use a RL agent aimed at optimizing energy savings wit pi_optimal.
Problem Statement
The goal is to develop an RL agent with pi_optimal that can learn optimal policies for adjusting cooling intensity in a building to minimize energy consumption while maintaining comfortable indoor conditions. The agent will be trained on historical data of building energy consumption and indoor temperature to learn the optimal policy for controlling the cooling intensity.
Dataset Overview
The dataset contains information about the energy consumption of multiple buildings, including environmental variables, system states, control actions, and energy consumption. The goal is to use this data to train an RL agent that can learn optimal policies for controlling building temperature settings.
Features
-
Building Characteristics:
episode: Unique identifier for each building.
-
Environmental Variables:
step: Timestep during the data collection.hour: Hour of the day of the data collection.day_type: Day of week of the data collection.outdoor_dry_bulb_temperature: Outdoor temperature (in °C).occupant_count: Number of occupants in the building.
-
System State:
indoor_dry_bulb_temperature: Current indoor temperature of the building (in °C).indoor_dry_bulb_temperature_cooling_set_point: Cooling set point for the indoor temperature (in °C).
-
Control Actions:
cooling_device: Cooling action applied to the building (between 0 (low intensity) - 1 (high intensity)).
-
Energy Consumption:
net_electricity_consumption: Net electricity consumption of the building (in kWh).
import pandas as pd
df_historical_building_energy_consumption = pd.read_csv('data/historical_temperature_control.csv')
df_historical_building_energy_consumption
| episode | step | hour | day_type | outdoor_dry_bulb_temperature | occupant_count | indoor_dry_bulb_temperature | indoor_dry_bulb_temperature_cooling_set_point | cooling_device | net_electricity_consumption | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 5 | 24.66 | 3.0 | 23.098652 | 23.222221 | 0.276068 | 0.677881 |
| 1 | 0 | 1 | 2 | 5 | 24.07 | 3.0 | 22.234743 | 22.222221 | 0.301041 | 0.846281 |
| 2 | 0 | 2 | 3 | 5 | 23.90 | 3.0 | 22.223060 | 22.222221 | 0.741433 | 5.384543 |
| 3 | 0 | 3 | 4 | 5 | 23.87 | 3.0 | 22.222250 | 22.222221 | 0.034795 | 1.809869 |
| 4 | 0 | 4 | 5 | 5 | 23.83 | 3.0 | 22.222237 | 22.222221 | 0.982480 | -0.319520 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1435 | 1 | 715 | 20 | 6 | 31.98 | 1.0 | 27.234158 | 25.000000 | 0.500844 | 3.809461 |
| 1436 | 1 | 716 | 21 | 6 | 29.92 | 1.0 | 23.156075 | 25.000000 | 0.635849 | -0.431024 |
| 1437 | 1 | 717 | 22 | 6 | 28.48 | 1.0 | 22.199642 | 25.000000 | 0.316609 | 1.092676 |
| 1438 | 1 | 718 | 23 | 6 | 27.27 | 1.0 | 22.608816 | 25.111110 | 0.047373 | 3.072868 |
| 1439 | 1 | 719 | 24 | 6 | 26.26 | 1.0 | 24.088943 | 25.555555 | 0.119994 | -0.409238 |
1440 rows × 10 columns
Speeding Up Training and Inference with sklearnex
In case you have an intel cpu, you can speed up the training and inference by uncommenting the following lines. This will enable the use of the Intel(R) Extension for Scikit-learn* (sklearnex) package, which accelerates the training and inference of scikit-learn models on Intel CPUs. This package is optional and can be installed using the following command:
pip install sklearnex
# Uncomment the following lines for faster training and inference if you have sklearnex installed and are using an Intel CPU
#import numpy as np
#from sklearnex import patch_sklearn
#patch_sklearn()
Reward Calculation
The reward balances two key objectives:
- Maintaining the indoor temperature close to the desired temperature (comfort).
- Minimizing energy consumption (cost).
We define the reward as the negative sum of:
- The squared deviation of the indoor temperature from the desired temperature (penalizing discomfort).
- The energy consumption, weighted by a factor to balance its impact.
# Desired indoor temperature
DESIRED_TEMP = 22 # Celsius
# Function to calculate reward
def calculate_reward(row):
# Temperature comfort penalty
temp_penalty = (row['indoor_dry_bulb_temperature'] - DESIRED_TEMP) ** 2
# Energy cost
energy_cost = row['net_electricity_consumption'] * 0.001
# Total penalty
total_penalty = temp_penalty + energy_cost
# Reward is the negative of the total penalty
reward = -total_penalty
return reward
# Apply the reward calculation
df_historical_building_energy_consumption['reward'] = df_historical_building_energy_consumption.apply(calculate_reward, axis=1)
df_historical_building_energy_consumption.head()
| episode | step | hour | day_type | outdoor_dry_bulb_temperature | occupant_count | indoor_dry_bulb_temperature | indoor_dry_bulb_temperature_cooling_set_point | cooling_device | net_electricity_consumption | reward | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 5 | 24.66 | 3.0 | 23.098652 | 23.222221 | 0.276068 | 0.677881 | -1.207714 |
| 1 | 0 | 1 | 2 | 5 | 24.07 | 3.0 | 22.234743 | 22.222221 | 0.301041 | 0.846281 | -0.055951 |
| 2 | 0 | 2 | 3 | 5 | 23.90 | 3.0 | 22.223060 | 22.222221 | 0.741433 | 5.384543 | -0.055140 |
| 3 | 0 | 3 | 4 | 5 | 23.87 | 3.0 | 22.222250 | 22.222221 | 0.034795 | 1.809869 | -0.051205 |
| 4 | 0 | 4 | 5 | 5 | 23.83 | 3.0 | 22.222237 | 22.222221 | 0.982480 | -0.319520 | -0.049070 |
Explanation of Reward Components
-
Temperature Penalty:
This penalizes larger deviations from the desired indoor temperature, encouraging the system to maintain comfort.
-
Energy Cost:
This adds a cost proportional to energy consumption, incentivizing energy efficiency.
-
Reward:
The reward is the negative of the total penalty, guiding the agent to minimize discomfort and energy usage simultaneously.
Dataset Preparation
First, we need to load and preprocess the building energy dataset to prepare it for training a pi_optimal RL agent. The pi_optimal package offers a custom dataset class that handles the entire preprocessing pipeline, making setup straightforward. A few parameters need to be defined for this process.
-
Unit Index: This parameter,
unit_index, specifies the different units for which we have data. In our case, these units are the different buildings. -
Time Column: Specifying the time column allows the model to recognize the temporal order of events and use historical data to make predictions. For example, the agent we are goging to build should lookback the last 12 hours for make a decision. This history length can be set by the
lookback_horizonparameter (see the documentation for more details). -
Reward Column: Here, we define the column that the agent will try to maximize. In this case, the dataset already includes an
rewardcolumn, which we calulated before hand. -
State Columns: The state columns represent the state of the system, which, in our case, is each building. This should include all relevant columns that influence the building’s energy consumption and environmental conditions. For example,
outdoor_dry_bulb_temperature,occupant_count, andday_typemay all impact reward, in our case the energy effiency given holding a desired temperature. -
Action Columns: Finally, we define the columns that represent actions that can be taken to achieve optimal results. In this case, we can adjust just the
cooling_device. Nevertheless pi_optimal is able to handle multiple actions at the same time.
By setting up these parameters, we effectively prepare our dataset for training the RL agent in pi_optimal. This configuration enables the agent to understand the structure of the data and optimize building energy savings effectively.
import pi_optimal as po
LOOKBACK_TIMESTEPS = 12
historical_dataset = po.datasets.timeseries_dataset.TimeseriesDataset(df=df_historical_building_energy_consumption,
lookback_timesteps=LOOKBACK_TIMESTEPS,
unit_index='episode',
timestep_column='step',
reward_column='reward',
state_columns=['day_type', 'hour', 'outdoor_dry_bulb_temperature', 'indoor_dry_bulb_temperature','occupant_count', 'net_electricity_consumption', 'indoor_dry_bulb_temperature_cooling_set_point'],
action_columns=['cooling_device'])
Agent Initialization and Training
With the dataset prepared, the next crucial step is to initialize and train the Reinforcement Learning (RL) agent. The agent will learn to model the environment of the building to make optimal decisions later with new data.
from pi_optimal.agents.agent import Agent
agent = Agent()
agent.train(dataset=historical_dataset)
Evaluation and Action Prediction
After training the Reinforcement Learning (RL) agent, the next step is to evaluate its performance on new, unseen data. This involves loading the current building energy consumption data, preparing it using the same preprocessing pipeline as the historical dataset, and then using the trained agent to predict the optimal actions (i.e. in our case cooling intensity) to maximize energy savings and maintain an desiried temperature.
import pandas as pd
import pi_optimal as po
# Load the current building energy consumption data
df_current_building_energy_consumption = pd.read_csv('data/current_temperature_control.csv')
# Apply the reward calculation
df_current_building_energy_consumption["reward"] = df_current_building_energy_consumption.apply(calculate_reward, axis=1)
# Create a new dataset for the current building energy consumption
current_dataset = po.datasets.timeseries_dataset.TimeseriesDataset(df=df_current_building_energy_consumption,
dataset_config=historical_dataset.dataset_config,
train_processors=False,
is_inference=True)
# Predict the best actions
best_actions = agent.predict(current_dataset)
Recommended Actions
With the agent’s recommended actions in hand, we can now inspect these suggestions and decide on the best way to implement them in the building control system.
Decision-Making Options
-
Full Application of Recommended Actions: We could choose to apply all recommended actions immediately, adjusting the cooling intensity according to the agent's suggestions for the entire time horizon (e.g., the next 4 hours). This approach allows the building control system to operate based on the agent’s full plan.
-
Incremental Application: Alternatively, we might apply only the first action in the sequence for the next hour and then the next hour re-run the agent to generate updated recommendations. This method provides flexibility by allowing adjustments based on real-time conditions, while still leveraging the agent’s ability to look multiple steps ahead.
for i in range(len(best_actions)):
print(f"Timestep {i}:")
print("Cooling device strength:", round(best_actions[i][0], 2))
print()
print("--------------------")
print()
Timestep 0:
Cooling device strength: 0.83
--------------------
Timestep 1:
Cooling device strength: 0.78
--------------------
Timestep 2:
Cooling device strength: 0.74
--------------------
Timestep 3:
Cooling device strength: 0.6
--------------------
Multi-Step Decision Planning
It's important to note that even when applying actions one step at a time, the agent’s recommendation for the immediate next step considers the impact over a broader horizon (e.g., the next 4 hours). This multi-step foresight enables the agent to make decisions that balance immediate energy savings with future efficiency, optimizing building performance over time.
By carefully choosing how to implement the recommended actions, we can maximize energy savings while maintaining adaptability to changing conditions.
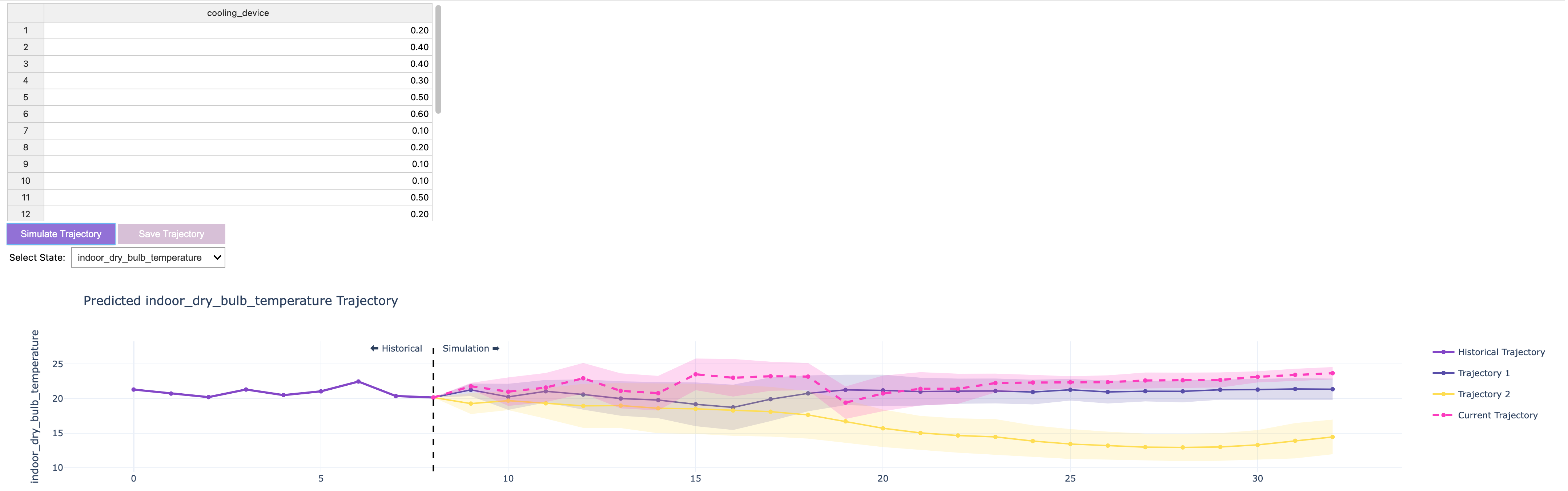
Simulating the Agent's Actions
The package also contains a visuzalizer for the simulated optimal trajectory. This simulator allows you to experiment with the agent's recommendations and observe how they impact energy consumption and indoor temperature over time. This tool can help you understand the agent's behavior and evaluate its performance in different scenarios.
from pi_optimal.utils.trajectory_visualizer import TrajectoryVisualizer
trajectory_visualizer = TrajectoryVisualizer(agent, current_dataset, best_actions=best_actions)
trajectory_visualizer.display()